2025년 회고
2025년은 정리보다 진행이 앞섰던 한 해였습니다. 연구와 일, 그리고 개인적인 사건들이 동시에 겹치면서 무엇을 이뤘는지보다 무엇을 미뤄두고 지나왔는지가 더 또렷하게 남았습니다. 이 글은 성과를 정리하기 위한 기록이 아니라, 한 해를 통과하며 쌓인 생각들을 미뤄둔 집청소를 하듯 하나씩 꺼내놓는 회고입니다.
지금까지 Python으로는 간단한 코드만 작성해 와서, 성능에 대한 고민을 별로 해 본 적이 없었습니다. 최근에 연구를 위해 십만 단위의 데이터를 Python으로 다룰 수밖에 없는 일이 생겼는데, 지금까지 작성해 오던 방식으로는 속도가 매우 느린 것 같았습니다. 제 코드를 수정하는 과정에서 알게 된 Python 코드의 실행 시간을 줄이기 위한 몇 가지 최적화에 대해서 정리해 보았습니다.

Python은 인터프리터 언어입니다. 인터프리터 언어는 코드를 한 번에 한 줄씩 읽어 들여서 실행하는 식이지요. 그렇다 보니 매번 코드를 탑재하고 기계어로 바꾸는 과정을 거치다 보니 컴파일러를 사용하는 언어에 비해 그 실행 속도가 느릴 수밖에 없습니다. 하지만 미리 소스 코드를 바이트 코드 형태로 변환해서 저장해 놓는 Just-In-Time 컴파일러를 이용하면 어느 정도 이를 개선 할 수 있습니다.
코드 빨리 돌리고 싶으면, PyPy 돌리면 대충 될 겁니다.
귀도 반 로섬, Python의 창시자
Python의 JIT 컴파일러에는 Numba, PyPy, Psyco 등이 있는데, 개인적으로는 설치도 간편하고 코드를 수정해주지 않아도 되는 PyPy가 가장 사용하기 편리했던 것 같습니다.
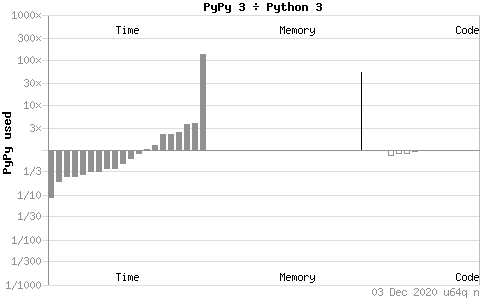
대부분의 경우에서 PyPy는 Cython이나 Python에 비해 2-3배 정도의 성능 향상을 보여주지만, File 읽고 쓰기가 잦은 경우나, Unicode를 다룬다거나, Tuple을 정렬하는 등의 경우, C 확장 모듈을 호출하는 등의 경우에는 Python이나 Cython보다 느린 경우가 나온다고 합니다. 운 좋게도, 저의 경우에는 파일 읽고 쓰기가 잦은 편임에도 불구하고, PyPy를 적용하는 것을 통해 약 2.1배 정도의 성능향상을 보여 주었습니다.
여러 Python JIT나 실행 환경을 시도해보고 가장 좋은 성능을 내는 실행 환경을 이용하는 것이 가장 좋다는 것으로 결론을 낼 수 있겠습니다.
output = []
for element in large_list:
if some_filter(element):
output.append(element)
어떤 리스트에서 조건에 맞는 값을 추출한 새로운 출력을 만들어 내는 코드를 그냥 작성한다면 위와 같을 것입니다. 위의 코드는 조금 복잡해 보이니, filter를 써서 조금 더 단순하게 만들면 다음과 같습니다.
output = list(filter(lambda x: some_filter(x), large_list)
저는 위와 같이 많이 작성해 오고는 했는데요, 전자가 후자보다 아주 조금 빠릅니다. 하지만 위의 두 코드 모두 느린 편입니다. 아래와 같이 List Comprehension을 사용하면 약 2배 정도 더 빠르게 값을 추려낸 새로운 리스트를 얻을 수 있습니다.
output = [x for x in large_list if some_filter(x)]
저는 Python에서 String을 합칠 때는 아무 생각 없이 다음과 같은 Naive Concatenation을 사용하곤 했습니다.
out_str = ''
for num in xrange(loop_count):
out_str += `num`
하지만 이런 방식은 여러 번 반복하게 되면, 매번 new_string을 메모리에 올리는 과정을 거쳐야 하므로 매우 느려집니다. 저의 경우에는 문자열 List를 만들어서 맨 마지막에 join을 하는 것을 통해서 속도를 상당히 개선할 수 있었습니다. 55만 개의 데이터를 합치는 데에 2400초 정도의 시간이 걸렸었는데, 이를 약 800초 정도로 줄일 수 있었습니다. (순수하게 문자열 합치기만 한 것이 아니라 튜플 탐색 등이 포함된 시간이긴 합니다.)
str_list = []
for num in xrange(loop_count):
str_list.append(`num`)
return ''.join(str_list)
String 합치기 속도에 대해 알아보면서 알게 된 것 중에 놀라운 것은, 임시 파일을 만들어서 값을 써놓고 파일의 값을 한번에 불러오는 방식이 위의 리스트를 이용한 방식보다 약 30% 정도 빠르다는 사실입니다.
컴퓨터들은 대부분이 여러 개의 코어를 가지고 있습니다만, Python은 하나의 코어만을 활용하여 연산을 수행합니다. 동시성을 충분히 고려하여 안전하게 작동시킬 수 있는 코드라면, Multi-processing을 통해서 연산에 사용하는 코어의 개수를 늘여 더 빠르게 연산 결과를 얻을 수 있습니다. 그 성능 향상은 코어의 개수에 비례한다고 합니다.
아직 제가 작성 중인 코드에는 적용을 해보지 못하였지만, 조만간에 적용해 보고 그 성능 향상 효과에 대해 글을 쓰도록 하겠습니다.
위에서 설명했던 방식들은 대부분이 어떤 도구를 이용하여 설계의 변경 없이 속도를 개선하는 방법들입니다. 하지만 대부분의 경우에는, 설계된 프로그램의 시간 복잡도를 최적화하여 극적인 성능개선을 얻을 수 있는 경우가 많았습니다. 코드마다 설계와 최적화 방식이 다르기 때문에 정확히 예를 들기는 어렵습니다만, 설계의 시간 복잡도를 고려해 보고, 어떻게 하면 시간 복잡도를 낮출 수 있을지 고민하는 과정이 필수적으로 필요합니다.
Python Wiki - Performance Tips
Efficient String Concatenation in Python
When is PyPy slower than Python? - Codeforces
The Little Book of Python Anti-Patterns — Python Anti-Patterns documentation
Sebastian Witowski - Writing faster Python
Python Interpreters Benchmarks